Recurrent PPO RL in Wumpus world
Spring 2026
Purpose:
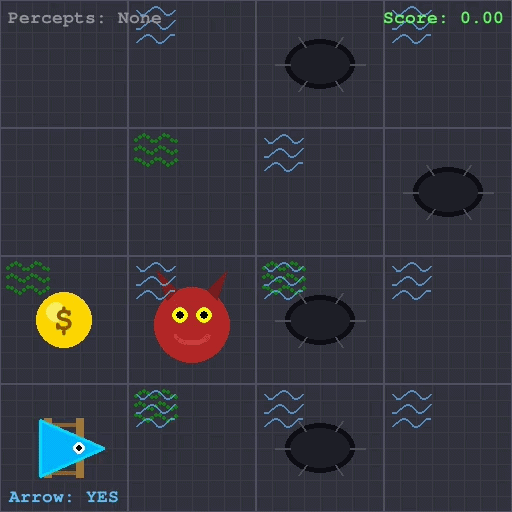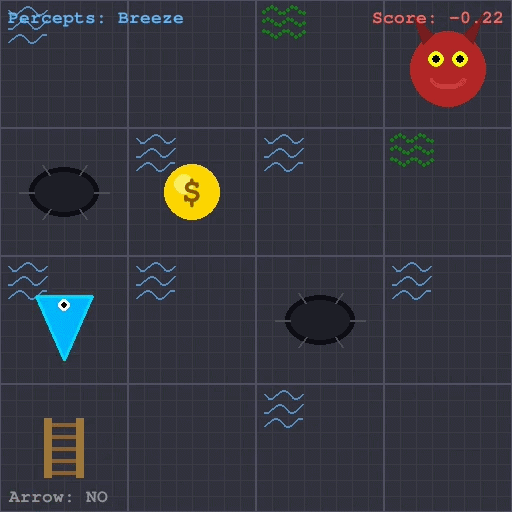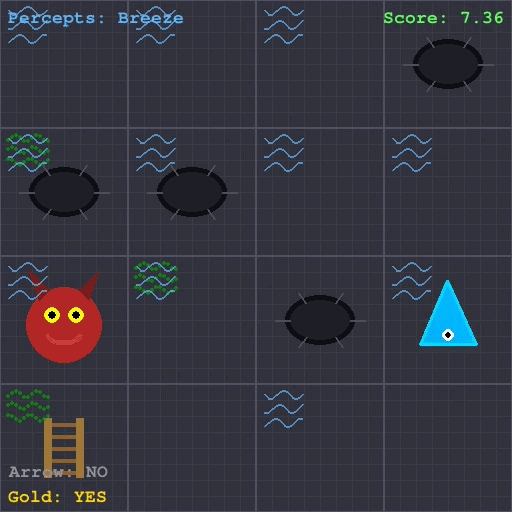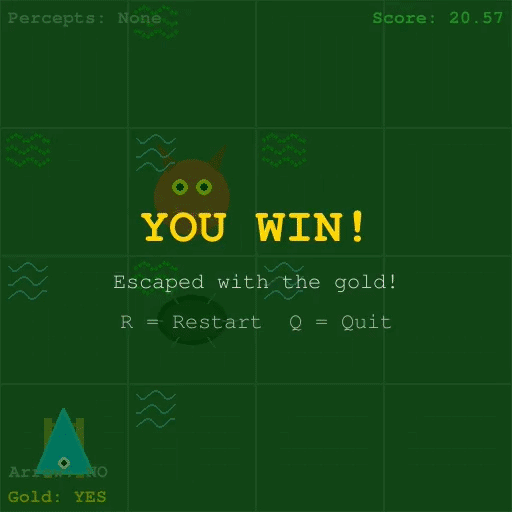
The goal of this project was to train a reinforcement learning agent to reliably navigate and win the classic Wumpus World problem, as described in Russell and Norvig’s AI: A Modern Approach. Wumpus World poses a particularly difficult challenge for RL due to its partial observability, sparse and delayed terminal rewards, and the lethal consequences of exploration.
To address these challenges,I implemented Proximal Policy Optimization (PPO) augmented with a Long Short-Term Memory (LSTM) network, enabling the agent to maintain a compressed memory of past observations. Combined called a Recurrent PPO.